这里提一下,我维护的几三个记录个人学习笔记以及社区中其它大佬们的优秀博客链接的仓库都获得了不少star,感谢读者们的认可,我也会继续在开源社区多做贡献。github主页:https://github.com/BBuf ,欢迎来踩

0x0. 前言
我之前解读过causal linear attention的cuda实现,文章见:https://zhuanlan.zhihu.com/p/673896906 ,也是在评论区通过@sonta 了解到了flash-linear-attention的Chunkwise并行实现。上篇文章https://mp.weixin.qq.com/s/H6wWBxwIJNCzkIlH_uIuiw中说到后续想继续解析一下chunk_rwkv6的实现,chunk_rwkv6的实现思路仍然是沿用flash-linear-attention中的Chunkwise并行思路,由于之前没有认真看过这个Chunkwise的算法所以读起来有点困难,这里需要用普通并行以及RNN递归的视角去看待才能理解这个算法流程。这篇文章就从 Gated Linear Attention Transformers with Hardware-Efficient Training (https://arxiv.org/pdf/2312.06635) 这篇Paper对线性Attention的Chunwise并行讲解和伪代码入手深入理解下这个方法,另外我们也会在后面深入分析下代码的实现。这篇Paper的作者也是flash-linear-attention的作者。
0x1. Paper部分
Paper部分这里只关注Background里面和Linear Attention相关的两节。这里对其进行翻译和解读。

我们首先简要介绍一下线性注意力层的背景。对于符号表示,我们使用黑体大写字母表示矩阵(例如,S、Q),黑体小写字母表示向量(例如, q t q_t qt、 k t k_t kt),斜体大写字母表示可学习的参数矩阵(例如, W K W_K WK)。通常我们使用相同的字母表示矩阵的行,例如, q t q_t qt 表示矩阵 Q Q Q 的第 t t t 行。

2.1 并行和递归形式
标准的Transformers采用softmax注意力机制,该机制接受输入序列 X ∈ R L × d X \in \mathbb{R}^{L \times d} X∈RL×d(其中 L L L 是长度, d d d 是隐藏维度)并通过以下方式计算输出 O ∈ R L × d O \in \mathbb{R}^{L \times d} O∈RL×d:
Q , K , V = X W Q , X W K , X W V , O = softmax ( ( Q K T ) ⊙ M ) V , Q, K, V = XW_Q, XW_K, XW_V, O = \text{softmax}\left((QK^T) \odot M\right) V, Q,K,V=XWQ,XWK,XWV,O=softmax((QKT)⊙M)V,
其中 W Q , W K , W V ∈ R d × d W_Q, W_K, W_V \in \mathbb{R}^{d \times d} WQ,WK,WV∈Rd×d 是可学习的矩阵, M ∈ { − ∞ , 1 } L × L M \in \{-\infty, 1\}^{L \times L} M∈{−∞,1}L×L 是一个掩码,用于防止模型关注未来的token,即 M i j = 1 M_{ij} = 1 Mij=1 当 i ≥ j i \geq j i≥j 且 M i j = − ∞ M_{ij} = -\infty Mij=−∞ 当 i < j i < j i<j。 (这里我们假设一个简单的单头注意力。)上述的并行注意力形式可以在给定完整输入 X X X 的情况下并行计算 O O O,从而实现高效训练。然而,在推理过程中,Transformer必须使用以下递归形式:
q t , k t , v t = x t W Q , x t W K , x t W V q_t, k_t, v_t = x_t W_Q, x_t W_K, x_t W_V qt,kt,vt=xtWQ,xtWK,xtWV
o t = ∑ i = 1 t exp ( q t k i T ) v i ∑ i = 1 t exp ( q t k i T ) o_t = \frac{\sum_{i=1}^{t} \exp(q_t k_i^T) v_i}{\sum_{i=1}^{t} \exp(q_t k_i^T)} ot=∑i=1texp(qtkiT)∑i=1texp(qtkiT)vi
其根据当前token的表示 x t ∈ R 1 × d x_t \in \mathbb{R}^{1 \times d} xt∈R1×d 计算查询 ( q t ) ( q_t ) (qt)、键 ( k t ) ( k_t ) (kt)和值 ( v t ) ( v_t ) (vt)向量,并对键 { k 1 , … , k t } \{k_1, \ldots, k_t\} {k1,…,kt} 和值 { v 1 , … , v t } \{v_1, \ldots, v_t\} {v1,…,vt}(即 “KV Cache”)集合进行注意力计算。
线性注意力机制(Katharopoulos等人,2020)用一个具有相关特征映射 ϕ \phi ϕ 的核函数 k ( x , y ) k(x, y) k(x,y)替换 exp ( q t k i T ) \exp(q_t k_i^T) exp(qtkiT)(即, k ( x , y ) = ⟨ ϕ ( x ) , ϕ ( y ) ⟩ k(x, y) = \langle \phi(x), \phi(y) \rangle k(x,y)=⟨ϕ(x),ϕ(y)⟩)。

由于我们有
o
t
=
∑
i
=
1
t
ϕ
(
q
t
)
ϕ
(
k
i
)
⊤
v
i
∑
i
=
1
t
ϕ
(
q
t
)
ϕ
(
k
i
)
⊤
=
ϕ
(
q
t
)
∑
i
=
1
t
ϕ
(
k
i
)
⊤
v
i
ϕ
(
q
t
)
∑
i
=
1
t
ϕ
(
k
i
)
⊤
.
o_t = \frac{\sum_{i=1}^{t} \phi(q_t) \phi(k_i)^{\top} v_i}{\sum_{i=1}^{t} \phi(q_t) \phi(k_i)^{\top}} = \frac{\phi(q_t) \sum_{i=1}^{t} \phi(k_i)^{\top} v_i}{\phi(q_t) \sum_{i=1}^{t} \phi(k_i)^{\top}}.
ot=∑i=1tϕ(qt)ϕ(ki)⊤∑i=1tϕ(qt)ϕ(ki)⊤vi=ϕ(qt)∑i=1tϕ(ki)⊤ϕ(qt)∑i=1tϕ(ki)⊤vi.
设
S
t
=
∑
i
=
1
t
ϕ
(
k
i
)
⊤
v
i
S_t = \sum_{i=1}^{t} \phi(k_i)^{\top} v_i
St=∑i=1tϕ(ki)⊤vi和
z
t
=
∑
i
=
1
t
ϕ
(
k
i
)
⊤
z_t = \sum_{i=1}^{t} \phi(k_i)^{\top}
zt=∑i=1tϕ(ki)⊤其中
S
t
∈
R
d
×
d
,
z
t
∈
R
d
×
1
,
S_t \in \mathbb{R}^{d \times d}, z_t \in \mathbb{R}^{d \times 1},
St∈Rd×d,zt∈Rd×1, 我们可以将上述公式重写为一个 RNN,
S
t
=
S
t
−
1
+
ϕ
(
k
t
)
⊤
v
t
,
z
t
=
z
t
−
1
+
ϕ
(
k
t
)
⊤
,
o
t
=
ϕ
(
q
t
)
S
t
ϕ
(
q
t
)
z
t
.
S_t = S_{t-1} + \phi(k_t)^{\top} v_t, z_t = z_{t-1} + \phi(k_t)^{\top}, o_t = \frac{\phi(q_t) S_t}{\phi(q_t) z_t}.
St=St−1+ϕ(kt)⊤vt,zt=zt−1+ϕ(kt)⊤,ot=ϕ(qt)ztϕ(qt)St.
尽管已经探索了各种核函数 (Kasai 等, 2021; Peng 等, 2021; Choromanski 等, 2020),最近的工作发现一个线性核(即,将
ϕ
\phi
ϕ 设为恒等映射)在实践中无需正则化器也能很好地工作 (Qin 等, 2022)。这导致了一个(未正则化的)线性注意力层,其更新方程如下,
S
t
=
S
t
−
1
+
k
t
⊤
v
t
,
o
t
=
q
t
S
t
.
(
1
)
S_t = S_{t-1} + k_t^{\top} v_t, o_t = q_t S_t. \quad (1)
St=St−1+kt⊤vt,ot=qtSt.(1)
方程 1 清楚地表明,线性注意力层本质上是一个带有矩阵值隐藏状态
S
t
S_t
St 的线性递归层,通过外积
k
t
⊤
v
t
=
(
x
t
W
K
)
⊤
(
x
t
W
V
)
k_t^{\top} v_t = (x_t W_K)^{\top} (x_t W_V)
kt⊤vt=(xtWK)⊤(xtWV) 更新。
1
^1
1 因果线性注意力的并行形式,其复杂度仍然是
L
L
L 的二次方,公式如下,
O
=
(
(
Q
K
⊤
)
⊙
M
)
V
,
\mathbf{O} = \left((\mathbf{QK}^{\top}) \odot \mathbf{M}\right) \mathbf{V},
O=((QK⊤)⊙M)V,
其中
M
∈
{
0
,
1
}
L
×
L
\mathbf{M} \in \{0,1\}^{L \times L}
M∈{0,1}L×L 是一个掩码,使得
M
i
j
=
1
\mathbf{M}_{ij} = 1
Mij=1 当
i
≥
j
i \geq j
i≥j 时,且
M
i
j
=
0
\mathbf{M}_{ij} = 0
Mij=0 当
i
<
j
i < j
i<j 时。由于
M
\mathbf{M}
M 的存在,不可能利用矩阵乘法的结合性质将并行形式的复杂度从二次降低到线性。
2
^2
2
方程1的推导我没搞清楚怎么推出来的,大佬可以评论区指导下。
2.2 Chunkwise并行形式

线性注意力的逐chunk并行形式在并行和递归形式之间取得了平衡 (Hua 等, 2022; Sun 等, 2023a),并允许部分并行的训练。形式上,假设输入 X X X 现在被分割为不重叠的块,每个块的长度为 C C C。令 S [ i ] ∈ R d × d \mathbf{S}_{[i]} \in \mathbb{R}^{d \times d} S[i]∈Rd×d 表示处理 i i i 个块后的块级隐藏状态,即 S [ i ] : = S i C \mathbf{S}_{[i]} := \mathbf{S}_{iC} S[i]:=SiC。进一步设 Q [ i ] : = Q i C + 1 : ( i + 1 ) C + 1 ∈ R C × d \mathbf{Q}_{[i]} := \mathbf{Q}_{iC+1:(i+1)C+1} \in \mathbb{R}^{C \times d} Q[i]:=QiC+1:(i+1)C+1∈RC×d 为对应于第 i i i 块的查询向量;令 K [ i ] , V [ i ] , O [ i ] \mathbf{K}_{[i]}, \mathbf{V}_{[i]}, \mathbf{O}_{[i]} K[i],V[i],O[i] 类似地定义。然后我们有以下跨chunk递归公式(对于 i ∈ { 0 , 1 , . . . , L C − 1 } i \in \{0, 1, ..., \frac{L}{C} - 1\} i∈{0,1,...,CL−1}):
S [ i + 1 ] = S [ i ] + ∑ j = i C + 1 ( i + 1 ) C k j ⊤ v j ∈ R d × d . ( 2 ) \mathbf{S}_{[i+1]} = \mathbf{S}_{[i]} + \sum_{j=iC+1}^{(i+1)C} \mathbf{k}_j^{\top} \mathbf{v}_j \in \mathbb{R}^{d \times d}. \quad (2) S[i+1]=S[i]+∑j=iC+1(i+1)Ckj⊤vj∈Rd×d.(2)
这里 S [ 0 ] \mathbf{S}_{[0]} S[0] 可以初始化为零或者从前一个段的隐藏状态初始化。所有来自一个chunk的(即 K [ i ] ⊤ V [ i ] \mathbf{K}_{[i]}^{\top} \mathbf{V}_{[i]} K[i]⊤V[i])RNN 输入的和可以在 O ( C 2 d ) O(C^2 d) O(C2d) 时间内并行计算。块内并行计算的输出如下所示:
O [ i + 1 ] = Q [ i + 1 ] S [ i ] + ( ( Q [ i + 1 ] K [ i + 1 ] ⊤ ) ⊙ M ) V [ i + 1 ] , \mathbf{O}_{[i+1]} = \mathbf{Q}_{[i+1]} \mathbf{S}_{[i]} + \left((\mathbf{Q}_{[i+1]} \mathbf{K}_{[i+1]}^{\top}) \odot \mathbf{M}\right) \mathbf{V}_{[i+1]}, O[i+1]=Q[i+1]S[i]+((Q[i+1]K[i+1]⊤)⊙M)V[i+1],
其中 O [ i + 1 ] ∈ R C × d \mathbf{O}_{[i+1]} \in \mathbb{R}^{C \times d} O[i+1]∈RC×d。这里的“块内”组件 O [ i + 1 ] intra \mathbf{O}_{[i+1]}^{\text{intra}} O[i+1]intra 具有与公式 1 完全相同的并行形式,因此需要 O ( C 2 d + C d 2 ) O(C^2 d + C d^2) O(C2d+Cd2)。而“块间”组件 O [ i + 1 ] inter \mathbf{O}_{[i+1]}^{\text{inter}} O[i+1]inter 负责从前一个块的隐藏状态贡献,并且需要 O ( C d 2 ) O(C d^2) O(Cd2)。训练复杂度因此为 O ( L C ( C 2 d + C d 2 ) ) = O ( L C d + L d 2 ) O\left(\frac{L}{C}(C^2 d + C d^2)\right) = O(L C d + L d^2) O(CL(C2d+Cd2))=O(LCd+Ld2),当 L > d L > d L>d 时小于 O ( L 2 d ) O(L^2 d) O(L2d)。注意,将 C = L C = L C=L 恢复了并行形式,而 C = 1 C = 1 C=1 恢复了递归形式。
从Paper里对Linear Attention和Chunkwise Linear Attention的描述可以理解到Chunkwise计算中最重要的一点,那就是在chunk间我们在计算KV的时候是不受到causal mask限制的,我们可以用一个大的矩阵乘法并行计算所有chunk的KV。不过由于公式(2)是逐chunk更新的,我们在当前的chunk i i i位置只能看到这个 i i i前面的其它chunk的KV,这也是后面的计算公式里面有一个前缀和的原因。而在chunk内部,则必须根据原始的Causal Attention逻辑来计算,也就是 ( ( Q [ i + 1 ] K [ i + 1 ] ⊤ ) ⊙ M ) V [ i + 1 ] \left((\mathbf{Q}_{[i+1]} \mathbf{K}_{[i+1]}^{\top}) \odot \mathbf{M}\right) \mathbf{V}_{[i+1]} ((Q[i+1]K[i+1]⊤)⊙M)V[i+1]。
0x2. 完全并行以及Chunkwise版本的Linear Attention测试代码
这里贴一下使用完全并行的Causal Linear Attention和Chunkwise Linear Attention进行计算的代码。
import torch
from einops import rearrange
def naive_linear_attn(q, k, v):
q = q * (q.shape[-1] ** -0.5)
scores = torch.matmul(q, k.transpose(-1, -2))
mask = torch.triu(torch.ones(scores.shape[-2], scores.shape[-1], device=q.device), diagonal=1)
scores = scores.masked_fill(mask.bool(), float(0))
output = torch.matmul(scores, v)
return output
def torch_chunk_linear_attn(q, k, v, chunk_size=64):
q = rearrange(q, 'b h (n c) d -> b h n c d', c = chunk_size) * (q.shape[-1] **-0.5)
k = rearrange(k, 'b h (n c) d -> b h n c d', c = chunk_size)
v = rearrange(v, 'b h (n c) d -> b h n c d', c = chunk_size)
kv = k.transpose(-1, -2) @ v
kv = kv.cumsum(2)
kv = torch.cat([
torch.zeros_like(kv[:, :, :1]),
kv[:, :, :-1]
], dim=2)
inter = q @ kv # (b, h, n, c, d) @ (b, h, n, d, d) -> (b, h, n, c, d)
intra = ((q @ k.transpose(-1, -2)).masked_fill_(torch.triu(torch.ones(chunk_size, chunk_size, dtype=bool, device=q.device), diagonal=1), 0)) @ v
o = inter + intra
return rearrange(o, 'b h n c d -> b h (n c) d')
if __name__ == "__main__":
B = 4
H = 4
L = 1024
D = 100
dtype = torch.float32
require_grad = True
q = (torch.randn(B, H, L, D).to(dtype)).requires_grad_(require_grad)
k = (torch.randn(B, H, L, D).to(dtype)).requires_grad_(require_grad)
v = torch.randn(B, H, L, D).to(dtype).requires_grad_(require_grad)
o1 = torch_chunk_linear_attn(q, k, v)
o2 = naive_linear_attn(q, k, v)
print('o1: ', o1.sum())
print('o2: ', o2.sum())
代码非常短,读了0x1节就很好理解了,这里就不继续啰嗦了。需要注意的是对于这个例子,如果使用float16/bfloat16可能会发生溢出导致测试无法通过,所以需要使用float32来计算。
0x3. Chunkwise Linear Attention的优势
从0x1节已经看到,Chunwise Linear Attention是介于完全并行和RNN递归形式的一种平衡的方案,打破了在Causal mask逻辑下的类Linear Attention结构必须先算q*k的限制,例如在faster-transformers里面实现的Linear Attention(注意Linear Attention中的核函数是可选的,不一定是这篇paper里提到的indentity)使用了一个完整的cuda kernel并且经过一系列优化最终在cuda core上取得了不错的性能,但这个实现却是完全不如Chunkwise Linear Attention的实现的,因为它拆散了gemm无法在Tensor Core上运行。另外一个例子就是,对于RWKV6这种模型来说(请看 https://zhuanlan.zhihu.com/p/696054687),它的naive实现中全部都是elementwise算子(即使是cuda kernel实现也只是做了fuse):
def naive_recurrent_rwkv6(
q,
k,
v,
w,
u,
initial_state=None,
output_final_state=False
):
# 记录输入张量 q 的原始数据类型。
orig_dtype = q.dtype
# 将输入张量转换为 32 位浮点数类型。
q, k, v, w, u = map(lambda x: x.float(), (q, k, v, w, u))
# 获取query张量的形状信息。
batch_size, n_heads, seq_len, d_head_k = q.shape
# 获取值张量的形状信息。
_, _, _, d_head_v = v.shape
# 初始化注意力张量为全零张量,形状为 (B, H, D, D),在 GPU 上进行计算。
h = torch.zeros(batch_size, n_heads, d_head_k, d_head_v, dtype=torch.float32, device=q.device)
# 初始化输出张量为全零张量,形状同值张量 v
o = torch.zeros_like(v)
# 如果提供了初始状态 initial_state,则将注意力张量 h 更新为初始状态:
if initial_state is not None:
h += initial_state
# 对序列长度进行迭代,每次迭代处理一个位置的输入:
for i in range(seq_len):
q_i = q[:, :, i, :] # 获取当前位置的query张量。shape为[B, H, D]
k_i = k[:, :, i] # 获取当前位置的key张量。shape为[B, H, D]
v_i = v[:, :, i, :] # 获取当前位置的value张量。shape为[B, H, D]
# 获取当前位置的权重张量,并使用指数函数进行处理。shape为[B, H, D]
w_i = w[:, :, i].exp()
# 计算当前位置的键值乘积,elementwise操作。
# shape变化为[B, H, D, 1] * [B, H, D, 1] -> [B, H, D, 1]
kv_i = k_i[..., None] * v_i[..., None, :]
# 计算当前位置的注意力加权输出,都是elementwise操作。
# h的shape为[B, H, D, D]
# u[None, ..., None]的shape为[1, H, D, 1]
# q_i[..., None]的shape为[B, H, D, 1]
# h + u[None, ..., None] * kv_i 的shape为:
# [B, H, D, D] + [1, H, D, 1] * [B, H, D, 1] ->
# [B, H, D, D] + [B, H, D, 1] ->
# [B, H, D, D]
o_i = (h + u[None, ..., None] * kv_i) * q_i[..., None]
# 将当前位置的输出加入到输出张量中。
# o[:, :, i]的shape为[B, H, D],o_i.sum(-2)的shape为[B, H, D]
o[:, :, i] = o_i.sum(-2)
# 更新注意力张量 h
# h的shape为[B, H, D, D]
# w_i[..., None]的shape为[B, H, D, 1]
# kv_i的shape为[B, H, D, 1]
# h * w_i[..., None] 的shape为[B, H, D, D]也是element-wise操作
h = h * w_i[..., None] + kv_i
return o.to(orig_dtype)
而使用上Chunwise的算法之后,通过一些工程努力就可以把这个代码改成部分矩阵乘的方式,从而使用TensorCore。当序列长度越来越长时,相比于rwkv6的当前实现就可以获得更多的加速。
当然,使用Chunkwise来写各种Linear Attention架构也需要做出一些工程上的努力,看到这个库都是用Triton来实现的,相比于cuda阅读起来会简单非常多,后续有机会再继续阅读。
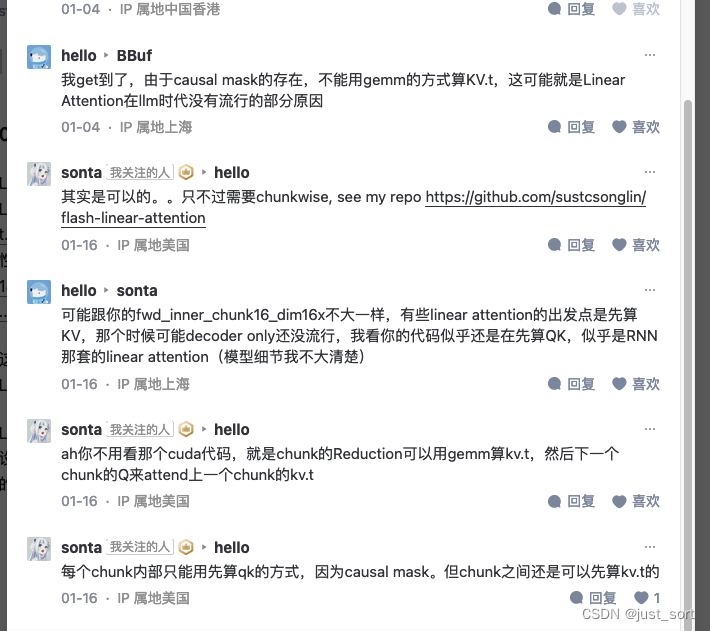
贴一下作者之前在我写的那个Linear Attention CUDA实现文章下的截图,也算是第一次从评论区学到了一个很棒的算法,respect。

0x4. 总结
本文解读了一下flash-linear-attention中的Chunkwise并行算法,希望对从事Linear Attention研究或者工程优化的读者拓宽视野有帮助。